Issue with nic driver on HPE servers after updating HPE drivers on ESXi 6.5 and 6.7
What happened
I ran into an issue the other day with a vCenter Server Appliance filling up one of its partitions. The partition that was filling up was the /storage/seat partition. This partition holds the postgres SQL database, so the vCenter server was in trouble.
After some digging around I realized that the root cause was a new event error from all ESXi hosts, that was coming at a rapid pace. The errors had started during the last driver and base updates, and only the HPE servers was affected.
Troubleshooting
If your seat partition is filling up, you can check what is causing the problem using your vCenter Management interface. It is located at https://yourserver:5480
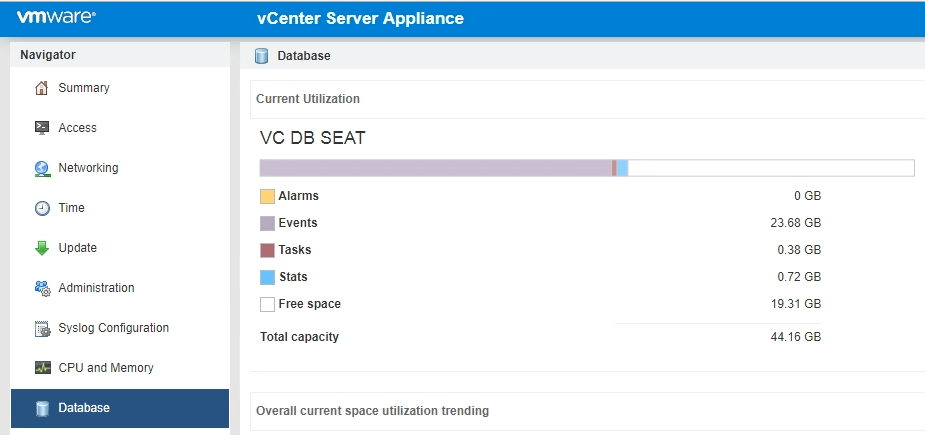
Here you can clearly see that the Events are the main occupant of space in the seat partition.
If it is not obvious what is causing the events size to grow like this, you can log in to the vCenter appliance and check the top 10 events in the database.
# Connect to vCenter using ssh # Enable the shell shell.set --enabled true # Start the postgres manager cd /opt/vmware/vpostgres/current/bin ./psql -d VCDB -U postgres # Query your database (This is for 6.5) SELECT COUNT(EVENT_ID) AS NUMEVENTS, EVENT_TYPE, USERNAME FROM VPXV_EVENT_ALL GROUP BY EVENT_TYPE, USERNAME ORDER BY NUMEVENTS DESC LIMIT 10;
For reference and other versions of vCenter you can check out this VMware KB: https://kb.vmware.com/s/article/2119809
Quick FIX
There are both quick fixes and solutions to this issue. If your vCenter service is down, you can get it back up quickly by just expanding the disk, and restarting vCenter.
The steps you need to perform is first to expand the vmdk in your appliance. You do not need to shutdown the VM to do this, but you cannot have any snapshots during this operation. That reminds me. Be sure to have a backup. This is not what I would consider a high risk operations, but if is definitely done at your own risk, so cover you back.
You seat partition will normally be Hard disk 8, but check just to make sure. You can check in the following way.
# Connect to vCenter using ssh # Enable the shell shell.set --enabled true # Run command to check disk sizes df -h # Run command to check disk number pvs
Using the command df -h you can check the Size of the disk and compare it to the size shown in vSphere Web Client when expanding you disk. The seat disks normal initial size is 10 GB.
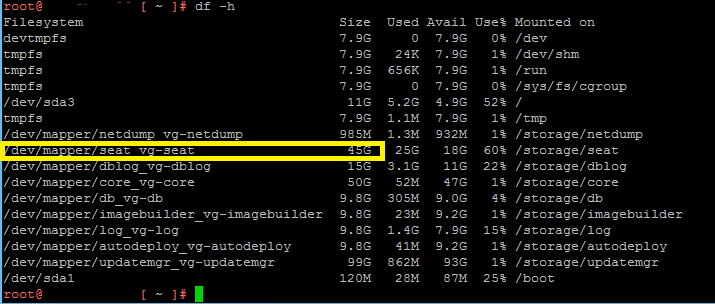
The pvs command will show you the disk and lvm correlation. The disk are numbered /dev/sd[number]. a=1, b=2, c=3 and so on. So h would be 8.

Now you just have to increase the disk size on the vCSA VM, like you would normally do on any VM. After the expansion you can take a snapshot for added safety. WARNING: In case you increased the size of the wrong disk. DO NOT TRY TO DECREASE THE DISK SIZE AGAIN. It will most likely not end well for you.

You now have to increase the partition size. VMware made a script to handle this operation. It will check all the partitions and expand them if the disks has been made larger.
# vCenter 6.5 Process # Connect to vCenter using ssh # Enable the shell shell.set --enabled true # Run command to expand your partition /usr/lib/applmgmt/support/scripts/lvm_cfg.sh storage lvm autogrow # You can inspect the result with the df commmand df -h
# vCenter 6.7 Process # Connect to vCenter using SSH # Run command to expand your partition com.vmware.appliance.version1.system.storage.resize # Enable the shell shell.set --enabled true # You can inspect the result with the df commmand df -h
More information can be found in this VMware kb: https://kb.vmware.com/s/article/2145603
If for some reason you are unable to fix the issued right now by using the next steps, you can prohibit vCenter events from growing quite so much by settings vCenter so that it does not keep events as long. The normal event retention is 30 days, but I recommend settings this to at least 180 days for audit reasons. Right now we will be setting it to 7 days. Beware that you will lose all events older than 7 days. You do not need to do this if you are able to fix the issue right away, only if you need to keep it running for a while with this error.
To set the retention you have to go to you vSphere Web Client.
- Go to Hosts and Clusters view.
- Select you vCenter in the top left tree.
- Go to Configure tab
- Select General section
- Click Edit
- Select Database section
- Set Event retention (days) to 7
- Click OK
- Set Task retention (days) to 7
- Make sure that Event cleanup is enabled.
- Click OK
- Restart vCenter

SOLUTION
Now for fixing the issue, you have to perform the following steps on each ESXi server what is having the issue. You can check them by selected them in the Host and Cluster view, and going to Monitor, Tasks and Events and then selecting the Events section. You will see the following errors:
Description Type Date Time Task Target User Alarm 'Host error' on ServerName triggered by event 27362228 'Issue detected on ServerName in Cluster: (unsupported) Device 10fb does not support flow control autoneg (2018-07-03T17:00:44.478Z cpu25:65661)' Error 03-07-2018 19:00:52 ServerName Description Type Date Time Task Target User Alarm 'Host error' on ServerName triggered by event 27362227 'Issue detected on ServerName in Cluster: (2018-07-03T17:00:44.478Z cpu25:65661)' Error 03-07-2018 19:00:52 ServerName
Googling this I found that Ali Hassan had a solution on his blog: https://www.alihassanlive.com/e2k3/2018/3/29/10fb-does-not-support-flow-control-autoneg-vmware-esx-65
I just did not want to download an older driver and putting it into production. I did not feel that it was a supported solution, so instead I decided to file a support request. The VMware representative informed me that this was a known bug, and that they had an internal kb on this issue. The solution was to enable the old driver, but on the servers I was working on, we did not need to install another driver, since the old driver was already there.
You can check what driver you are using by enabling SSH on one of your hosts, and connecting to it. (If you do not know how, you can read about it here: https://pubs.vmware.com/vsphere-6-5/index.jsp?topic=%2Fcom.vmware.vcli.getstart.doc%2FGUID-C3A44A30-EEA5-4359-A248-D13927A94CCE.html)
# Connect to ESXi host using ssh # Run command to check whatr driver you are currently using esxcfg-nics -l # Run command to list the relevant driver available esxcli software vib list | grep ixg
I had two drivers available. ixgben and net-ixgbe, and I was using the ixgben driver.
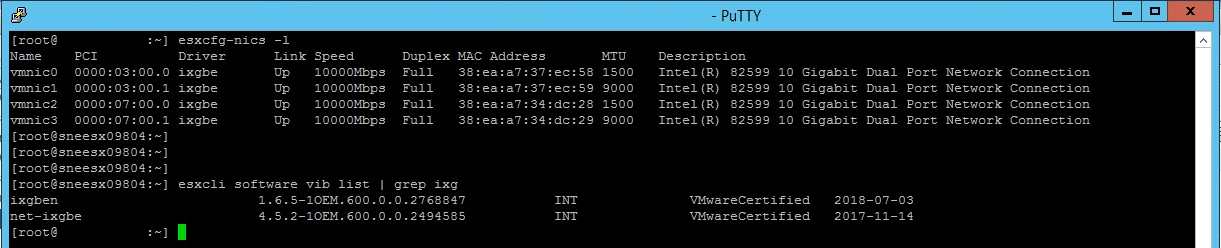
I needed to change to the ixgbe driver. For some reason you refer to it with ixgbe, and not net-ixgbe.
The process on each host to switch the drivers is as follows:
- Put host into maintenance mode
- Enable SSH
- Connect to host with SSH
- Check the driver to make sure
- Enable the old driver
- Disable the new driver
- Save configuration
- Reboot host
- Disable SSH
- Take out of maintenance mode
- Next host
# Enable new driver esxcli system module set -e=true -m=ixgbe # Disable old driver esxcli system module set -e=false -m=ixgben #Save configuration /sbin/auto-backup.sh
I hope you found this article helpful.
Update: HPE recognised this bug, and made an advisory about it: https://support.hpe.com/hpsc/doc/public/display?docId=emr_na-a00057927en_us
Also Allan wrote more about it on his blog: https://www.virtual-allan.com/10fb-does-not-support-flow-control-autoneg/
Update: VMware created a KB dedicated to the problem: https://kb.vmware.com/s/article/59218?lang=en_US
thanks so much for this help. Worked like a charm to swap back to our other driver since HPe latest bundles during updates are still not including the Intel NIC fix of driver version 1.7.10 that the HPE Customer Advisory published in October 2018. Strange VMware hasn’t bundled this out as a bug/NIC fix either or issue through a potential bug VIB fix especially since HPE even directs you over to download the NIC driver though VMware hosting the download fixes.
One Correction to the headline of the article…this is applicable to our ESXi 6.7 hosts as well not just 6.5. We are running HPE DL580 Gen9 systems with Intel(R) 82599 10 Gigabit Dual Port Network Connection NIC models. The “ixgben” currently installed that has started experiencing flow control errors is 1.4.1-12vmw.650.2.50.8294253 (6.5host) & 1.7.1-10OEM.670.0.0.7535516 (6.7host). This was AFTER we implemented the latest SPP from HPe that the errors started occurring. Again HPE failing to bundle the appropriate Intel NIC driver version into its GRAND big daddy SPP nor its VMware customized SPP bundles.
Thank you for the heads up. I will add it to the article.
also should mention in our vCSA6.7 the script is called autogrow.sh and not the old lvm_cfg.sh script which is no longer present in the directory
I updated with the commands for 6.7